Technology has changed the way in which authors are able to do business with publishers, whether for traditional paper-based publications or for their own institutional publications. It has also made possible the use of online repositories both for collecting and publishing material in electronic form as well as for providing long-term storage and reference facilities.
Some aspects of repositories, both technical and managerial, need careful attention if they are to avoid the dangers of obsolescence and maintain the ability of users to find and refer to the items stored.
When the only medium of publication was paper, authors were accustomed to settling down for a long wait between having an article or a book accepted, and seeing it appear. The lengthy lead times were a result of complex manual processes and slow communications, both within the publishing and printing businesses as well as within the authors' disciplines and institutions.
Publication on paper nevertheless provides a form of distributed repository, because it goes to an institutionally diverse and geographically widespread audience. It is relatively inaccessible—you have to travel to see a document or wait for an inter-library loan—and the locations are recorded only in the mailing lists of the publisher and in library catalogues. But despite the apparent fragility of paper, it has been remarkably resistant to destruction and deterioration over the centuries.
The low quality of much contemporary paper is not an encouraging sign for the future.
Most of the traditional publishing processes shown in are still in use. The increased use of ICT has so far largely been restricted to an increase in speed, not a change in the fundamental nature of the publishing cycle itself. The canonical example of this is the use of email, web, and FTP between publisher and author, publisher and reviewers, and publisher and printer. An exception is the use of electronic publishing for the author to produce camera-ready copy, which can have its own advantages and disadvantages.
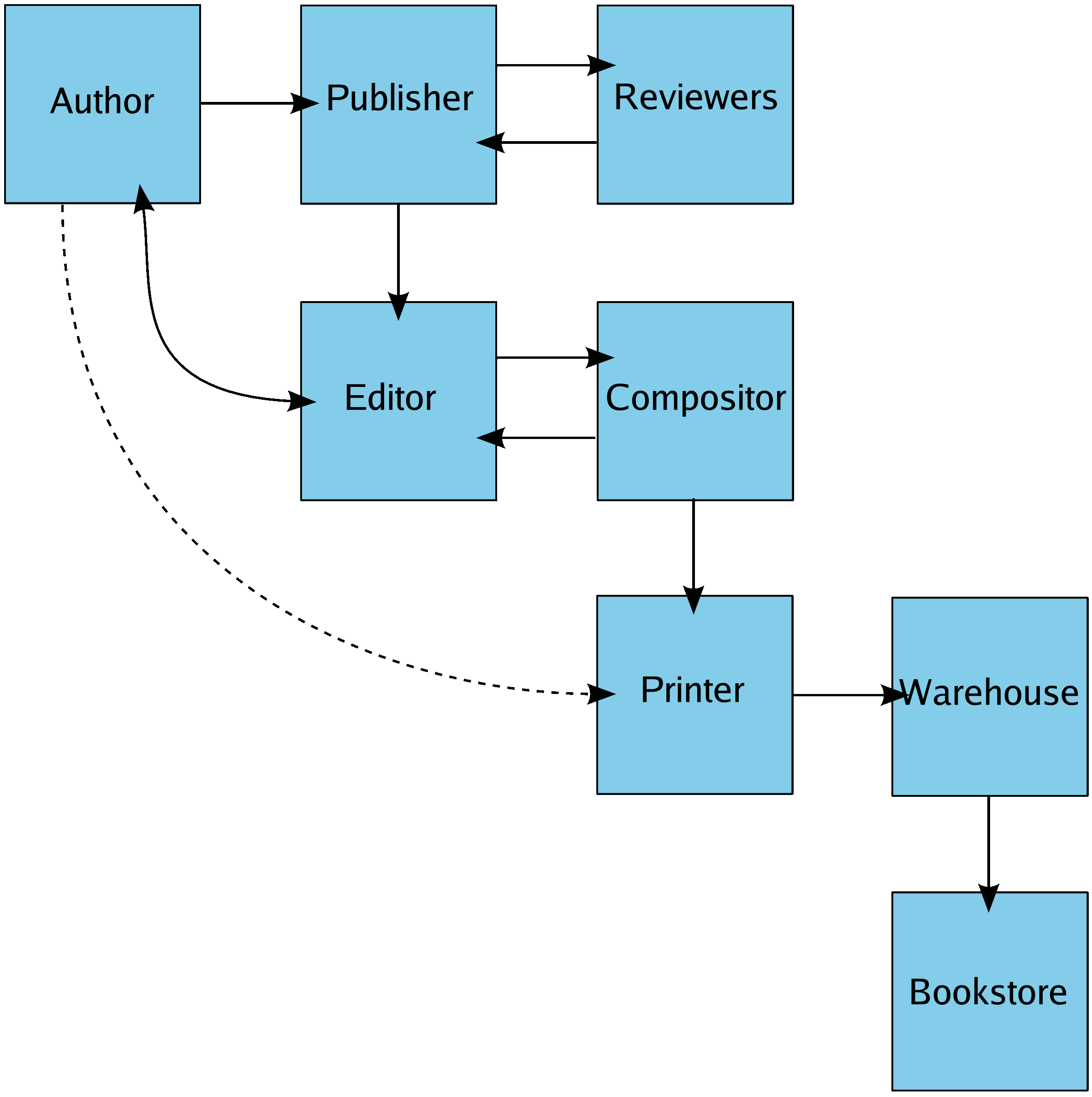
The dashed line represents the route taken by the finished document when the author generates final-format output (camera-ready copy), bypassing the conventional composition process.
Although such technologies used to be cited as the barriers defeating greater use of electronic publishing—see, for example, []—human and organisational factors can still emerge as the bottlenecks: arranging the peer review process; synchronising submissions for multiple-author publications; and handling negotiations with printers and other subcontractors ([]).
The increase in communications speed has also revealed a number of other underlying factors whose delays were previously masked by slow communication. Foremost amongst these is the task of formatting or reformatting the book or article, even—or perhaps especially—in the case already mentioned, when the author has undertaken to provide camera-ready copy. Another is the increased administrative and manual workload in the publishers' production processes caused by additional production tasks like the insertion of CDs or DVDs in a book, and the re-checking for validity of URIs quoted in the text.
The advance of CIT not only requires new skills, but places an entirely new set of tools in the hands of the author as well as the publisher. Both groups can make use of web-based services (web sites, blogs, wikis, and mediation systems) as well as web-based access to new as well as traditional network services (email, newsgroups, bulletin-boards, FTP servers, SMS, podcasts, and more). These tools can be used for communication between the parties to a publication, but they can also be used for the act of publication itself.
This is not lost on authors, who are demanding better services from publishers before, during, and after publication, and particularly in respect of their readership. Notoriously in the field of Physics, authors demanded and got—or rather, took—the ability to make preprints available on the web, in defiance of the publishers' unfounded misgivings about loss of journal sales. A more conservative approach can be seen in the public access policy of the US National Institutes of Health, which now encourages authors to make their articles available on the web immediately they have been published on paper ([]).
Translating this to an institutional framework, it has been the case for many years that works can be made available within the institution as well as on the Internet—before, during, after, and in some cases instead of, formal publication by a recognised (paper) publisher. In the case of self-publication, the workflow can be reduced to that shown in . In some cases the institution itself—possibly in the form of an established project or service—has taken on the role of publisher.

Whether the route is institutional publication or self-publication, there are several priorities for authors and contributors:
ease of use;
safe keeping;
a point of publication or exposure;
a place of reference or citation.
Institutional and national priorities may place other demands on the system, particularly in a competitive environment where access to funding is partly dependant on the visibility of information.
Marketing will have an important role to play in publicising the existence of a system, and thereby raising the standing of the institution—or, indeed, the nation. But in a sceptical and Internet-aware community, a network-accessible service tends to depend far more on its reputation for reliability and accuracy than on corporate pronouncements.
There has been considerable debate on the merits or otherwise of building and populating the repository first, and considering preservation later, with entire conferences (for example at the RLG) devoted to arguing both sides of the question. Unfortunately, retrofitting the repository for preservation at some later date is technically and managerially more demanding than doing it at the time of submission.
There is also a serious risk that the ease of use of search engines will end up being taken as a substitute for preservation and reference. The web is not yet at a stage of development where URIs can be considered stable. This means that if a search conducted online returns only online references, they cannot be regarded as a long-term resource because they will eventually deteriorate and break.
Ultimately, in the eventual absence of printed publications, only reliable metadata is capable of solving this problem, by providing stable and verifiable pointers to authorship, topics, dates, and authorities. Librarians have known this for decades, but authors and even editors still regard it as a burdensome chore to add.
Given the facility for each author to publish information independently on the web, it is clear that the result of each author using their own server is fragmented distribution, which is not useful to readers. Despite the advances in search engines, finding reusable information can still be hard, and there is still little incentive for authors to include machine-readable metadata in documents they publish on the web.
Many institutions, individuals, and projects therefore provide managed collections of information—textual, graphical, audio, video, and more—where the reader can search, browse, and download whole documents or document fragments.
Here and elsewhere I use the term ‘document’ to refer to objects in all media, not just text.
The nature of a repository means it can have several dimensions or axes, depending on the requirements of the users and the type of information stored:
Static collections hold items which by their nature never change—historical, literary, religious, and other documents of record. They can be added to, but are only ever changed to correct demonstrable errors.
Dynamic collections are constantly being updated, with old items moved to archive, new items added, and current items being modified.
Thematic collections concentrate on specific topics, requiring careful management to remain within their remit.
General collections are all-embracing, although they may be divided into sub-collections which are thematic.
Integral collections deal in whole documents, whatever the medium. They may offer fragmentary abstraction, but the storage concentrates on entire entities.
Fragmentary collections offer extracts and subsets of documents, especially for use in circumstances where whole documents would be inappropriate.
Repositories may offer additional benefits and restrictions such as restricted access for sensitive material, privileges for authorised users to add or remove items, and supporting material such as analyses, bibliographies, or commentaries.
From the foregoing, it is possible to identify a certain core set of features and requirements which are common to most repositories, although some are applicable only to certain types of document:
Where appropriate, the hosting organisation must undertake that the facility will continue in existence for the foreseeable future, and that suitable provision will be made for this continuance (this usually involves a political and financial commitment);
The address or location must not change (or at least, aliases or redirects must be kept active); searching must always return a usable URI;
Each item in the collection must come with sufficient referencing metadata for it to be referred to accurately off-line;
The agent of placement must be identified and must authenticate the source or derivation;
The hosting organization must undertake to preserve the data across time and technological change;
It should not involve undue effort to submit an item, or update or withdraw it.
While permanence is obviously desirable, it is probably unattainable in today's environment, where a change in governance can lead to sudden repudiation of an institutions's efforts simply by removing sources of funding. It is therefore important that individuals whose contributions comprise the content of a repository should be aware that they still have a responsibility to their colleagues to retain a copy of their submissions.
Research or teaching information in textual or graphical format includes several different classes of documents not normally found in formal repositories or archives. The formal collections tend to concentrate on conventional peer-reviewed publications—whether on paper or in electronic form, including traditional books and articles as well as e-journals. The additional material may have special needs, and may include any of the following:
Personal or institutional web sites, blogs, wikis, mailing list and newsgroup archives, and other electronic resources;
(those not published by the traditional processes): theses, reports, essays, bibliographies, reviews, slide presentations, notes, etc;
(those which cannot be published in isolation by the traditional processes): series of photographs, films, sound recordings, maps, CDs/DVDs, screenshots, data files, etc;
(material often intended for reuse or citation, or in developing other documents): quotes, video and audio clips, pictures, references, recommendations, and other short or abbreviated items.
Creating collections of these items is challenging because of the diversity, and there is a strong temptation to retain the original format of submission, no matter how esoteric or unsuitable, because of the effort involved in regularising the matter. Unless the file and data formats themselves have a historical or authentic importance, this temptation must be avoided, and all items rigorously stored in an agreed and accessible format.
Most institutions have until now been content to allow their staff and students to store their research information and results in arbitrary formats which slowly become unusable as technology leaves them behind. In part this laisser-faire approach is due to lack of information about the dangers of entropy and bit-rot, but it is also partly due to an unwillingness to interfere. In many cases, the information in these documents is now only accessible from a paper copy, not from the original files. This can lead to unnecessary delay and expense in scanning or retyping the information in order to put it online, and this may be costed in addition to the time and money—especially that of any funding agency—originally spent putting the information into a non-reusable format in the first place.
With the current pressure to compete for research funding on past performance rather than future promise, especially from agencies who have funded the institution before, it is no longer acceptable for the results of earlier investments to have become inaccessible or unusable. Both the physical format (cards, disk, tape, or chip) and the logical format (file type) need to be generated, managed, and maintained in a manner that will outlast the researchers involved.
There is precedent for this in copyright law, where copyright continues to subsist in a work for 75 years after death.
For short-term, ephemeral, or unimportant information, any immediately usable format will do: whatever is simplest and easiest. But in the same way that an architect or an engineer or a geographer would never consider using bitmaps for diagrams, or an art historian consider using lossy compression for master copies of reproductions, so it must be for the long-term storage of persistent information. The only acceptable format is one which can adapt itself to the circumstances of its use and remain free of external interference.
Having been dogmatic about the storage of information, it is for that very reason unwise to be dogmatic about the software. There are dozens of systems available, of which a handful will adequately cope with most requirements—but from a limited set of viewpoints. Each community which may be represented in the running of a repository (authors, contributors, librarians, archivists, IT specialists, academics, administrators, etc) will approach the problem from a different point of view, and thus see certain requirements as priorities which others will dismiss.
The point about being dogmatic over information storage is that if the format is sufficiently adaptable and free from interference, then it is almost irrelevant what software is used at any given stage. This approach gives the participating communities a wider choice over time, and has demonstrably contributed to the successful survival of numerous repositories over the years.